코드 리뷰
Transformer 코드 리뷰
우당탕탕코린이
2024. 1. 14. 18:56
kaggle 코드를 참고하였습니다.
1. Import Libraries
# importing required libraries
import torch.nn as nn
import torch
import torch.nn.functional as F
import math,copy,re
import warnings
import pandas as pd
import numpy as np
import seaborn as sns
import torchtext
import matplotlib.pyplot as plt
warnings.simplefilter("ignore")
print(torch.__version__)2. Basic components
- Create Word Embeddings
- 우선, input sequence의 각각의 단어를 embedding vector로 변환해야 한다.
- 각각의 embedding vector의 차원 : 512
- vocab size : 100
- embedding matrix의 차원 : 100*512
- batch size : 32
- sequence length : 10
- output size : 32 * 10 * 512
- 1개의 batch에 들어있는 32개의 sequence들은 각각 10개의 word들로 구성되어있고, word 하나의 차원은 512이다.
class Embedding(nn.Module):
def __init__(self, vocab_size, embed_dim):
"""
Args:
vocab_size: size of vocabulary (100)
embed_dim: dimension of embeddings (512)
"""
super(Embedding, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
def forward(self, x):
"""
Args:
x: input vector
Returns:
out: embedding vector
"""
out = self.embed(x)
return out- Positional Encoding
- 모델이 각각의 문장 내에서의 단어들의 위치를 파악하기 위해서 진행해야 한다.
- "attention is all you need" 논문에서는 홀수번째에는 cos function을. 짝수번째에는 sin function을 사용했다.

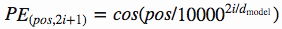
- pos : 문장에서의 해당 단어의 순서
- i : embedding vector 차원 상에서의 위치
- Positional embedding은 embedding matix와 동일한 행렬을 생성할 것이다.
- seuence에서의 각각의 단어들이 1*512 차원의 embedding vector를 갖고 있었을 때, position embedding은 각각의 단어들에 동일하게 1*512 차원인 positional vector를 추가할 것이다.
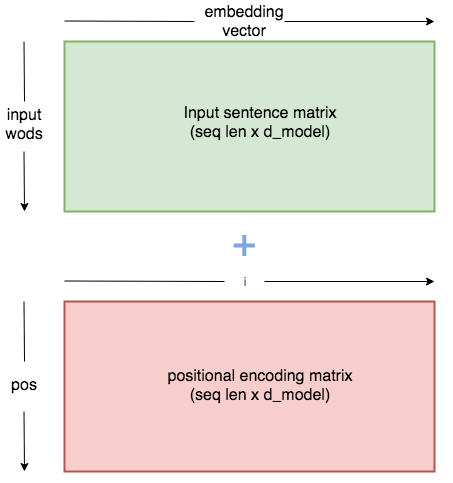
- 위의 예시는 batch size가 32, sequence length가 10, embedding dimension이 512인 경우이다.
- 앞서 말했듯이 embedding vector의 차원은 32*10*512이다.
- 이 때, positional encoding matrix의 차원 역시 32 * 10 * 512가 되는 것이다.
class PositionalEmbedding(nn.Module):
def __init__(self,max_seq_len,embed_model_dim):
"""
Args:
seq_len: length of input sequence (10)
embed_model_dim: demension of embedding (512)
"""
super(PositionalEmbedding, self).__init__()
self.embed_dim = embed_model_dim
pe = torch.zeros(max_seq_len,self.embed_dim)
for pos in range(max_seq_len):
for i in range(0,self.embed_dim,2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/self.embed_dim)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1))/self.embed_dim)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: input vector
Returns:
x: output
"""
# make embeddings relatively larger
x = x * math.sqrt(self.embed_dim)
#add constant to embedding
seq_len = x.size(1)
x = x + torch.autograd.Variable(self.pe[:,:seq_len], requires_grad=False)
return x- Self Attention
- self attention이란?
- 하나의 sequence 내에서 각각의 단어들간의 dependency를 바탕으로 한 벡터를 생성함.
- 작동 과정
- Step1 : Key, Query, Value vector 계산하기
- key, query, value vector를 만들어서 이들 행렬을 학습시킨다.
- batch size = 32, sequence length = 10, embedding dimension = 512
- output의 dimension : 32*10*512
- 이를 32*10*8*64로 resize해야 한다.
- 이때, 8은 multi-head attention에서의 head의 수.
- Step2 : query matrix와 key matrix의 내적 계산하기
- Q*K.t
- key, query, value의 차원은 모두 32*10*8*64라고 가정한다.
- 이때, 계산의 편의를 위해 transpose를 진행해줘야 한다. 진행 후에는 32*8*10*64
- 이제 계산을 진행하면, (32*8*10*64) * (32*8*64*10) -> (32*8*10*10)
- Step3 : 이제, output matrix를 key matrix의 차원의 루트값으로 나눈 뒤 이에 softmax를 적용한다.
- key matrix의 차원은 64이므로, 이의 루트값은 8이다.
- Step4 : step3에서 계산한 값을 value matirx와 곱한다.
- step3의 output은 32*8*10*10이다. 이를 (32*8*10*64)와 곱하면 output dimension은 (32*8*10*64)가 된다.
- Step5 : output을 linear layer에 통과시킨다. 이것이 multihead attention의 최종 output.
- (32*8*10*64)를 (32*10*8*64)로 다시 transpose한 후, 이를 (32*10*512)로 reshape한다.
- (32*10*512)를 linear layer에 통과시키면 (32*10*512)가 된다.
- Step1 : Key, Query, Value vector 계산하기
- self attention이란?
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim=512, n_heads=8):
"""
Args:
embed_dim: dimension of embeding vector output (512)
n_heads: number of self attention heads (8)
"""
super(MultiHeadAttention, self).__init__()
self.embed_dim = embed_dim #512 dim
self.n_heads = n_heads #8
self.single_head_dim = int(self.embed_dim / self.n_heads) #512/8 = 64 . each key,query, value will be of 64d
#key,query and value matrixes #64 x 64 -> 왜...?
self.query_matrix = nn.Linear(self.single_head_dim , self.single_head_dim ,bias=False) # single key matrix for all 8 keys #512x512
self.key_matrix = nn.Linear(self.single_head_dim , self.single_head_dim, bias=False)
self.value_matrix = nn.Linear(self.single_head_dim ,self.single_head_dim , bias=False)
self.out = nn.Linear(self.n_heads*self.single_head_dim ,self.embed_dim)
def forward(self,key,query,value,mask=None): #batch_size x sequence_length x embedding_dim # 32 x 10 x 512
"""
Args:
key : key vector
query : query vector
value : value vector
mask: mask for decoder
Returns:
output vector from multihead attention
"""
batch_size = key.size(0) # 32
seq_length = key.size(1) # 10
# query dimension can change in decoder during inference.
# so we cant take general seq_length
seq_length_query = query.size(1)
# step1
# 32x10x512
key = key.view(batch_size, seq_length, self.n_heads, self.single_head_dim) #batch_size x sequence_length x n_heads x single_head_dim = (32x10x8x64)
query = query.view(batch_size, seq_length_query, self.n_heads, self.single_head_dim) #(32x10x8x64)
value = value.view(batch_size, seq_length, self.n_heads, self.single_head_dim) #(32x10x8x64)
k = self.key_matrix(key) # (32x10x8x64)
q = self.query_matrix(query)
v = self.value_matrix(value)
q = q.transpose(1,2) # (batch_size, n_heads, seq_len, single_head_dim) # (32 x 8 x 10 x 64)
k = k.transpose(1,2) # (batch_size, n_heads, seq_len, single_head_dim)
v = v.transpose(1,2) # (batch_size, n_heads, seq_len, single_head_dim)
# step2 : computes attention
# adjust key for matrix multiplication
k_adjusted = k.transpose(-1,-2) #(batch_size, n_heads, single_head_dim, seq_ken) #(32 x 8 x 64 x 10)
product = torch.matmul(q, k_adjusted) #(32 x 8 x 10 x 64) x (32 x 8 x 64 x 10) = #(32x8x10x10)
# fill those positions of product matrix as (-1e20) where mask positions are 0
if mask is not None: # decoder에서 사용할 예정.
product = product.masked_fill(mask == 0, float("-1e20"))
# step3
#divising by square root of key dimension
product = product / math.sqrt(self.single_head_dim) # / sqrt(64) (=8)
#applying softmax
scores = F.softmax(product, dim=-1)
# step4 : mutiply with value matrix
scores = torch.matmul(scores, v) ##(32x8x 10x 10) x (32 x 8 x 10 x 64) = (32 x 8 x 10 x 64)
# step5
#concatenated output
concat = scores.transpose(1,2).contiguous().view(batch_size, seq_length_query, self.single_head_dim*self.n_heads) # (32x8x10x64) -> (32x10x8x64) -> (32,10,512)
output = self.out(concat) #(32,10,512) -> (32,10,512)
return output3. Encoder

- Step1 : input은 embedding layer와 positional encoding layer를 통과한다.
- input : 32*10 (batch size=32, sequence length=10)
- input이 embedding layer를 지나면 32*10*512가 됨.
- 동일한 차원의 position encoding vector가 추가됨.
- 이 값은 multihead attention으로 들어간다.
- Step2 : multihead attention layer를 통과한다.
- multihead attention의 input은 32*10*512이다.
- key, query, value vector들을 통하여 생성된 output은 32*10*512가 될 것이다.
- Step3 : 이제 normalization과 residual connection 과정을 거칠 것이다.
- multihead attention의 output과 input vector를 더하고, layer 정규화를 진행.
- Step4 : Step3의 결과를 feed forward layer에 통과시킨 후, 이를 normalization layer에 통과시키고, input과의 residual connection을 진행시킨다.
class TransformerBlock(nn.Module):
def __init__(self, embed_dim, expansion_factor=4, n_heads=8):
super(TransformerBlock, self).__init__()
"""
Args:
embed_dim: dimension of the embedding (512)
expansion_factor: fator ehich determines output dimension of linear layer
n_heads: number of attention heads (8)
"""
self.attention = MultiHeadAttention(embed_dim, n_heads)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.feed_forward = nn.Sequential(
nn.Linear(embed_dim, expansion_factor*embed_dim),
nn.ReLU(),
nn.Linear(expansion_factor*embed_dim, embed_dim)
)
self.dropout1 = nn.Dropout(0.2)
self.dropout2 = nn.Dropout(0.2)
def forward(self,key,query,value):
"""
Args:
key: key vector
query: query vector
value: value vector
norm2_out: output of transformer block
"""
# step2 : multihead attention layer 통과
attention_out = self.attention(key,query,value) #32x10x512
# step3 : residual connection + normalization
# 근데 왜 attention_out과 value를 더하지?
# 다시 보니 embedding, positional output이 key, query, value네..
# 근데 꼭 value여야 하나? key나 query면 안되나??
attention_residual_out = attention_out + value #32x10x512
norm1_out = self.dropout1(self.norm1(attention_residual_out)) #32x10x512
# step4 : feed forward layer + normalization layer + residual connection
feed_fwd_out = self.feed_forward(norm1_out) #32x10x512 -> #32x10x2048 -> 32x10x512
feed_fwd_residual_out = feed_fwd_out + norm1_out #32x10x512
norm2_out = self.dropout2(self.norm2(feed_fwd_residual_out)) #32x10x512
return norm2_out
class TransformerEncoder(nn.Module):
"""
Args:
seq_len : length of input sequence (10)
embed_dim: dimension of embedding (512)
num_layers: number of encoder layers
expansion_factor: factor which determines number of linear layers in feed forward layer
n_heads: number of heads in multihead attention
Returns:
out: output of the encoder
"""
def __init__(self, seq_len, vocab_size, embed_dim, num_layers=2, expansion_factor=4, n_heads=8):
super(TransformerEncoder, self).__init__()
self.embedding_layer = Embedding(vocab_size, embed_dim)
self.positional_encoder = PositionalEmbedding(seq_len, embed_dim)
self.layers = nn.ModuleList([TransformerBlock(embed_dim, expansion_factor, n_heads) for i in range(num_layers)])
def forward(self, x):
# step1 : input(32*10) -> embedding vector(32*10*512)
embed_out = self.embedding_layer(x)
# step1 : embedding vector(32*10*512) + positional encoding vector(32*10*512)
out = self.positional_encoder(embed_out)
for layer in self.layers:
out = layer(out,out,out)
return out #32x10x512
4. Decoder
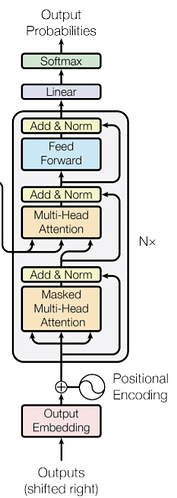
- Step1 : output은 우선 embedding과 positional encoding을 거친다.
- sequence length = 10, batch size = 32, embedding vector dimension = 512
- input size : 32*10
- output dimension : 32*10*512
- Step2 : embedding output은 masked multi-head attention을 거친다.
- Why mask?
- target words의 attention을 생성할 때, 미래의 단어들을 미리 들여다보면 안되기 때문에 사용한다.
- 뒷부분은 무한 음수(-1e 20)를 활용하여 masking함.
- Why mask?
- Step3 : Step2의 결과를 normalization하고, Step2의 input과 residual connect한다.
- Step4 : Step3의 결과를 Multi-head attention에 넣는다.
- 이 때, key vector와 value vector는 encoder의 output으로 가져온다.
- query vector는 이전 decoder의 output이다.
- Step4의 결과 역시 residual connection과 normalization을 거친다.
- Step5 : Step4의 결과를 feed forward layer에 넣고, 마찬가지로 add와 norm을 진행한다.
- Step6 : total target corpus의 단어 수와 동일한 길이의 linear layer에 결과를 통과시킨 후, softmax에 통과시켜 각 단어의 확률을 얻는다.
class DecoderBlock(nn.Module):
def __init__(self, embed_dim, expansion_factor=4, n_heads=8):
super(DecoderBlock, self).__init__()
"""
Args:
embed_dim: dimension of the embedding
expansion_factor: fator ehich determines output dimension of linear layer
n_heads: number of attention heads
"""
self.attention = MultiHeadAttention(embed_dim, n_heads=8)
self.norm = nn.LayerNorm(embed_dim)
self.dropout = nn.Dropout(0.2)
self.transformer_block = TransformerBlock(embed_dim, expansion_factor, n_heads)
def forward(self, key, query, x,mask):
"""
Args:
key: key vector
query: query vector
value: value vector
mask: mask to be given for multi head attention
Returns:
out: output of transformer block
"""
#we need to pass mask mask only to fst attention
attention = self.attention(x,x,x,mask=mask) #32x10x512
value = self.dropout(self.norm(attention + x))
out = self.transformer_block(key, query, value)
return out
class TransformerDecoder(nn.Module):
def __init__(self, target_vocab_size, embed_dim, seq_len, num_layers=2, expansion_factor=4, n_heads=8):
super(TransformerDecoder, self).__init__()
"""
Args:
target_vocab_size: vocabulary size of taget
embed_dim: dimension of embedding
seq_len : length of input sequence
num_layers: number of encoder layers
expansion_factor: factor which determines number of linear layers in feed forward layer
n_heads: number of heads in multihead attention
"""
self.word_embedding = nn.Embedding(target_vocab_size, embed_dim)
self.position_embedding = PositionalEmbedding(seq_len, embed_dim)
self.layers = nn.ModuleList(
[
DecoderBlock(embed_dim, expansion_factor=4, n_heads=8)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_dim, target_vocab_size)
self.dropout = nn.Dropout(0.2)
def forward(self, x, enc_out, mask):
"""
Args:
x: input vector from target
enc_out : output from encoder layer
trg_mask: mask for decoder self attention
Returns:
out: output vector
"""
# Step1
x = self.word_embedding(x) #32x10x512
x = self.position_embedding(x) #32x10x512
x = self.dropout(x)
for layer in self.layers:
# Step2
# 왜 처음 masked multihead attention input부터 key, value를 encoder output으로 제공하는거지??
x = layer(enc_out, x, enc_out, mask)
out = F.softmax(self.fc_out(x))
return out
전체 transformer 구조
class Transformer(nn.Module):
def __init__(self, embed_dim, src_vocab_size, target_vocab_size, seq_length,num_layers=2, expansion_factor=4, n_heads=8):
super(Transformer, self).__init__()
"""
Args:
embed_dim: dimension of embedding
src_vocab_size: vocabulary size of source
target_vocab_size: vocabulary size of target
seq_length : length of input sequence
num_layers: number of encoder layers
expansion_factor: factor which determines number of linear layers in feed forward layer
n_heads: number of heads in multihead attention
"""
self.target_vocab_size = target_vocab_size
self.encoder = TransformerEncoder(seq_length, src_vocab_size, embed_dim, num_layers=num_layers, expansion_factor=expansion_factor, n_heads=n_heads)
self.decoder = TransformerDecoder(target_vocab_size, embed_dim, seq_length, num_layers=num_layers, expansion_factor=expansion_factor, n_heads=n_heads)
def make_trg_mask(self, trg):
"""
Args:
trg: target sequence
Returns:
trg_mask: target mask
"""
batch_size, trg_len = trg.shape
# returns the lower triangular part of matrix filled with ones
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
batch_size, 1, trg_len, trg_len
)
return trg_mask
def decode(self,src,trg):
"""
for inference
Args:
src: input to encoder
trg: input to decoder
out:
out_labels : returns final prediction of sequence
"""
trg_mask = self.make_trg_mask(trg)
enc_out = self.encoder(src)
out_labels = []
batch_size,seq_len = src.shape[0],src.shape[1]
#outputs = torch.zeros(seq_len, batch_size, self.target_vocab_size)
out = trg
for i in range(seq_len): #10
out = self.decoder(out,enc_out,trg_mask) #bs x seq_len x vocab_dim
# taking the last token
out = out[:,-1,:]
out = out.argmax(-1)
out_labels.append(out.item())
out = torch.unsqueeze(out,axis=0)
return out_labels
def forward(self, src, trg):
"""
Args:
src: input to encoder
trg: input to decoder
out:
out: final vector which returns probabilities of each target word
"""
trg_mask = self.make_trg_mask(trg)
enc_out = self.encoder(src)
outputs = self.decoder(trg, enc_out, trg_mask)
return outputs