
데이터는 더 많이, 모델 크기는 작게

Meta에서 공개한 모델로, 전체적인 컨셉은 모델의 파라미터를 줄였지만, 성능은 올랐다!라는 컨셉이다.
1. Introduction
- Large Language Models (LLMs)이 텍스트 지시문이나, 굉장히 적은 예시만으로도(few-shot) 좋은 성능을 내는 데에는 충분한 크기의 모델이 조건으로 따라붙는다.
- 기존의 연구들은 "파라미터가 많아질수록, 더 좋은 성능이 따라온다"라는 가정 아래에서 진행되었다.
- 그러나, Hoffmann et al에서는 더 작은 모델에 더 많은 데이터를 학습시키면 더 큰 모델보다 좋은 성능을 낼 수 있음을 밝혔다.
- 본 논문에서는
LLaMA라는7B부터65B사이읭 파라미터들을 지닌 모델을 제안한다.LLaMA-13B는 크기가 10배 정도 차이나는GPT-3보다 대부분의 벤치마크 데이터셋에서 성능을 뛰어넘었다.- 또한, 모델의 크기를 줄이며 single GPU에서도 학습을 가능하게 하여 LLM 연구의 진입장벽을 낮췄다.
- 마지막으로, 가장 큰 65B llama의 경우에도 다른 best llm들인 Chinchilla와 PaLM-540B와도 경쟁력이 있다.
- 추가적으로, 다른 LLM들과는 다르게 llama는 학습에 공개된 데이터들만 사용하였다.
2. Approach
2.1. Pre-training Data
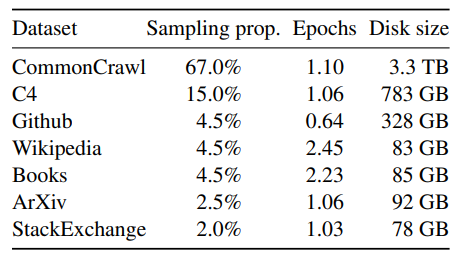
- training data는 Table 1에 나와있듯이 여러 소스들의 데이터들이 섞인 형태이다.
- 대부분의 데이터들은 다른 LLM의 학습에 사용된 데이터들을 재사용했고, 모두가 접근 가능한 데이터들만 사용했다.
- English CommonCrawl [67%]
- 2017년부터 2020년까지의 CommonCrawl 데이터들을 전처리했다.
- CCNet pipeline을 통하여 전처리 진행.
- 데이터 중복제거
- fastText 선형 분류기를 통하여 영어가 아닌 페이지 삭제 -> language indentification
- n-gram 언어 모델을 통해 퀄리티가 낮은 내용 삭제
- 추가적으로, 위키피디아의 reference로 사용된 페이지들과 랜덤하게 샘플링된 페이지들을 분류하는 선형 모델을 학습하여 reference가 아닌 페이지들은 삭제
- C4 [15%]
- 다양하게 전처리된 CommonCrawl 데이터셋을 활용하면 성능을 향상시킬 수 있다는 점을 발견하고 공개된 C4 데이터셋을 학습 데이터에 포함시킴.
- C4 데이터 전처리 과정
- 데이터 중복제거 (CCNet과 동일)
- language indentification (CCNet과 동일)
- 구두점 표시의 존재 유무, 단어의 수, 웹페이지의 문장들 등 heuristic한 방법들로 quality filtering 진행.
- Github [4.5%]
- Google BigQuery에서 이용 가능한 public GithHub dataset 사용
- Apache, BSD, MIT license 프로젝트들만 활용
- 전처리
- 코드 라인의 길이, 영숫자의 비율, header와 같이 반복적으로 비슷하게 쓰이는 코드들과 같은 요소들을 heuristic하게 제거하여 quality filtering 진행.
- file level에서 데이터 중복제거
- Wikipedia [4.5%]
- 2022년 6월~8월 간의 Wikipedia dump를 추가. (20종류의 언어로)
- 전처리
- 하이퍼링크, 코멘트, 그리고 기타 반복되는 boilerpalte들을 제거
- Gutenberg and Book3 [4.5%]
- 둘 다 book corpora
- Gutenberg Project : public domain의 책들을 포함
- Book3 : large language model들을 학습시킬 수 있는 공공 데이터.
- 전처리
- 책 단위에서의 중복 제거. (내용이 90% 이상 겹치면 제거)
- ArXiv [2.5%]
- 데이터셋에 과학적 데이터를 추가하기 위해 arXiv Latex 파일들을 추가.
- 전처리
- 참고문헌과 같은 요소들 제거
- .tex 파일들로부터 코멘트들을 제거
- 사용자들이 작성한 매크로들을 제거
- Stack Exchange [2%]
- 컴퓨터 과학부터 화학까지 다양한 분야에 관한 양질의 질문과 답변이 있는 웹사이트인 Stack Exchange의 dump를 포함시켰다.
- 28 largest 웹사이트들로부터 데이터를 모음
- 전처리
- 텍스트에서 HTML 태그들을 삭제
- 점수 순으로 정렬 (점수가 높은 것부터 낮은 쪽으로)
- Tokenizer
- byte-pair encoding (BPE) 알고리즘 사용
- SentencePice 적용
- 모든 숫자들을 각각의 숫자들로 나누고, byte들을 UTF-8 charater들로 대체.->무슨 얘기지..ㅠ
- 모든 학습 데이터들은 tokenization을 거친 후 대략적으로 1.4T 토큰들을 포함
- 대부분의 학습 데이터들은 1epoch 동안에만 학습되었고, Wikipedia 데이터와 book domain 데이터들만 예외로 2epoch 동안 학습되었다.
2.2. Architecture
- 최근의 다른 llm들과 유사하게, transformer 구조를 따른다.
- PaLM과 같은 다른 모델들에서 사용된 다양한 발전 기법들을 사용한다.
- Architecture 항목에서는 기존 transformer와 모델의 다른 점과, 영감을 받은 기존 모델들에 대해 소개한다.
- Pre-normalization [GPT3]
- 학습 시 안정성을 높이기 우해서, 각각의 트랜스포머의 sub-layer의 output을 정규화하는 대신, input에 정규화를 진행한다
- normalizing function으로는 RMSNorm을 활용했다
- SwiGLU activation function [PaLM]
- 성능 향상을 위해 비선형 활성화 함수인 ReLU를 SwiGLU로 대체했다.
- PaLM에서는 4d dimension을 사용하였으나, llama에서는 2/3 * 4d를 활용하였다.
- Rotary Embeddings [GPTNeo]
- 네트워크의 각 layer에 기존의 positional embedding을 제거하고, rotary positional embeddings (RoPE)를 사용했다.
- 모델별로 활용한 하이퍼 파라미터는 Table 2와 같다.

2.3 Optimizer
- llama의 optimizer setting
- AdamW optimizer
- cosine learning rate schedule
- 최종 learning rate는 최대 learning rate의 10%와 동일.
- weight decay = 0.1
- gradient clipping = 1.0
- warming step = 2,000
- 모델의 크기에 따라 learning rate와 batch size를 달리 함 (Table 2 참고)
2.4 Efficient implementation
- 모델의 학습 시간을 줄이기 위해 여러 최적화 기법 적용
- 메모리 사용량과 runtime을 줄이기 위해 casual multi-head attention을 효율적으로 사용
- attention 가중치들을 저장하지 않음
- 마스크된 key/query score를 계산하지 않음
- checkpointing될 때 backward 과정에서 재계산되는 activation의 양을 감소시킴
- linear layer의 output과 같이 계산 비용이 큰 activation들을 저장
- PyTorch autograd 대신에 transformer layer들의 backward function을 적용하는 방법을 활용
- 65B 모델을 학습시킬 때, 2048 A100 GPU(80GB RAM)에서 380 tokens/sec/GPU의 속도로 돌아갔음. 이는 1.4T 토큰을 포함하는 훈련 데이터셋은 대략 21일이 훈련하는 데 걸렸다는 얘기다.
3. Main results
- 기존 연구와 유사하게, 논문에서는 zero-shot과 few-shot task들을 수행했고, 총 20개의 benchmark들에 대한 결과를 서술했다.
- Zero-shot
- 모델에게 task에 대한 텍스트 설명과 문제를 함께 제공
- 모델은 자유 형태로 생성된 답 혹은 답변들의 순위를 제공한다.
- Few-shot
- 모델에게 task에 대한 1개에서 64개 정도의 몇몇 예시들을 문제와 함께 제공
- 모델은 정답을 생성하거나 여러 선택지가 있을 경우에는 순위를 함께 제공한다.
- LLaMA를 다른 기존의 유명한 모델들과 비교
- GPT-3, Gopher, Chinchilla, PaLM, GPT-J, GPT-Neo, OPT-IML, Flan-PaLM
- LLaMA를 free-form generation task들과 multiple choice task들에서 평가.
- Multiple choice task들에서의 평가 방법
- objective : 제공된 context를 통하여 생성된 option들 중에서 가장 적절한 응답을 선택한다
- 어떻게?
- option들 중에서 context와 가장 유사도가 높은 응답을 선택
- 해당 유사도에 응답의 텍스트 길이로 정규화 과정 진행. (해당 과정은 book dataset 제외)
- (정규화된 context와의 최대 유사도)/(선택된 응답과 실제 정답과의 유사도) 계산
- 어떻게?
- objective : 제공된 context를 통하여 생성된 option들 중에서 가장 적절한 응답을 선택한다
- Multiple choice task들에서의 평가 방법

3.1 Common Sense Reasoning
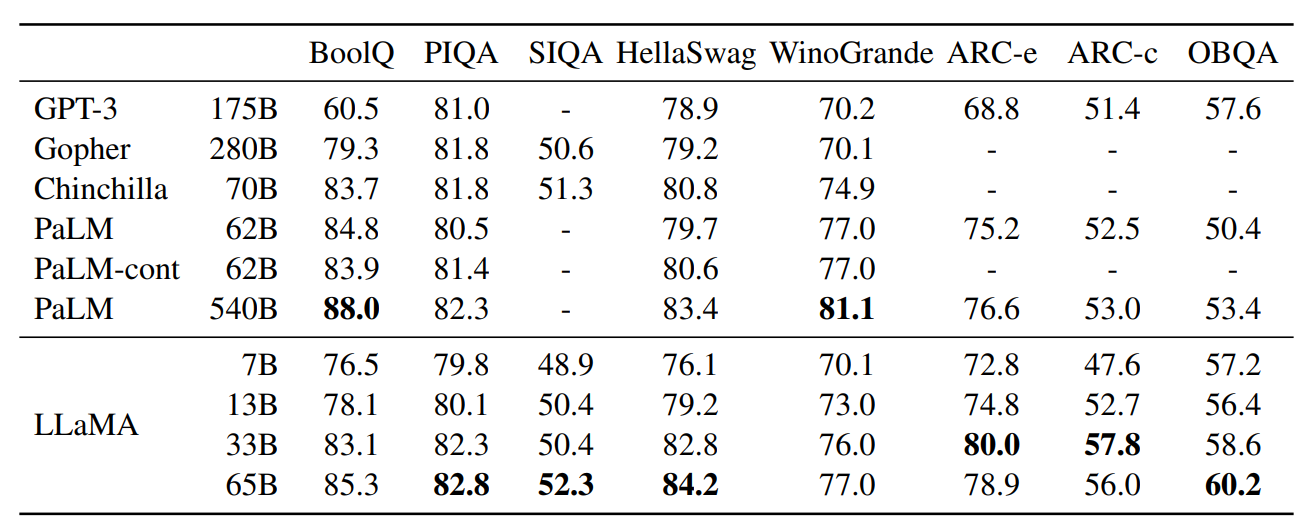
- 8개의 common sense reasoning benchmark들에 평가 진행
- BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA
- 이 데이터셋들은 Cloze(빈칸 메우기)와 Winograd style(대명사가 지칭하는 것 맞추기), 그리고 질문에 대한 복수 선택 task들을 포함한다
- zero-shot setting에서 평가를 진행했다.
- LLaMA-65B
- Chinchilla-70B보다 모든 benchmark에서 높은 결과를 냈다
- PaLM-540B보다 BoolQ와 WinoGrande를 제외한 모든 benchmark에서 높은 결과를 냈다
- LLaMA-13B
- GPT-3보다 모델의 크기가 10배 가까이 작음에도 불구하고 대부분의 benchmark에서 더 높은 결과를 냈다
3.2 Closed-book Question Answering


- 2개의 closed-book question answering benchmark들과 비교 -> Natural Questions(Table3), TriviaQA(Table4)
- 질문의 답의 근거를 포함하는 문서에 모델이 접근할 필요가 없는 closed book setting에서 exact match의 성능을 평가
- LLaMA-65B
- 두 벤치마크의 zero-shot과 few-shot setting에서 모두 SOTA를 달성.
- LLaMA-13B
- GPT-3와 Cinchilla보다 5~10배 더 작음에도 불구하고 충분히 경쟁력 있는 성능을 냈다.
3.3 Reading Comprehension

- RACE라는 reading comprehension benchmark를 통하여 평가
- 중국인 중고등학생들을 위하여 만들어진 영어 reading comprehension 시험들로부터 수집된 데이터.
- LLaMA-65B : PaLM-540B와 경쟁력 있음
- LLaMA-13B : GPT-3보다 성능이 좋음
3.4 Mathematical reasoning

- MATH와 GSM8k라는 2개의 mathematical reasoning benchmark들로 평가
- MATH : 12K 규모의 LaTeX로 작성된 중고등학생 수학 문제들
- GSM8k : 중학교 수학 문제들
- Minerva : 수학 웹페이지들과 ArXiv로부터 추출된 38.5B 토큰들로 finetuning된 PaLM 모델
- PaLM과 LLaMA는 모두 수학 데이터로 finetuning되지 않은 상태에서 결과 확인
- Maj1@k : 각 문제마다 k개의 샘플들을 생성하고 가장 많은 투표를 받은 정답을 선택
- LLaMA-65B : 수학적 데이터로 finetuning되지 않았음에도 불구하고 GSM8k 데이터에서 finetuning된 Minerva-62B보다 성능이 좋았다.
3.5 Code Generation
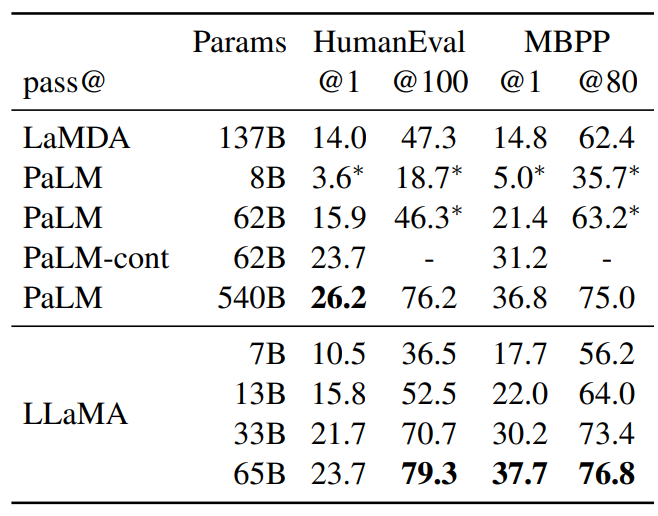
- HumanEval과 MBPP 벤치마크 데이터셋 활용
- 두 데이터 모두 모델이 몇몇 input-output 예시들과 프로그램에 대한 설명을 몇문장으로 받는다.
- HumanEval에서는 function signature도 제공받고, 프롬프트는 natural code로 작성된 텍스트 설명과 docstring으로 작성된 문제로 구성된다.
- 모델은 설명에 부합하고 테스트 케이스들을 통과하는 파이썬 프로그램을 생성해야 한다.
- 비교군의 모델들 중 PaLM과 LLaMA는 코드 토큰들과 유사함 수를 포함하는 데이터들로 훈련되었다.
- LLaMA 13B : LaMDA 137B를 모든 세팅에서 이김
- LLaMA 65B : 더 오래 학습된 PaLM 62B를 이김
- pass@1 : 0.1 temperature로 샘플링됨
- pass@100, pass@80 : 0.8 temperature 세팅
- PaLM-Coder와 같이 코드 데이터로 fine tunig을 진행하면 성능 향상이 있다는 기존 연구가 있었으므로, LLaMA 역시 fine tuning을 적용하면 해당 task의 성능이 올라갈 것이다!
3.6 Massive Multitask Language Understanding
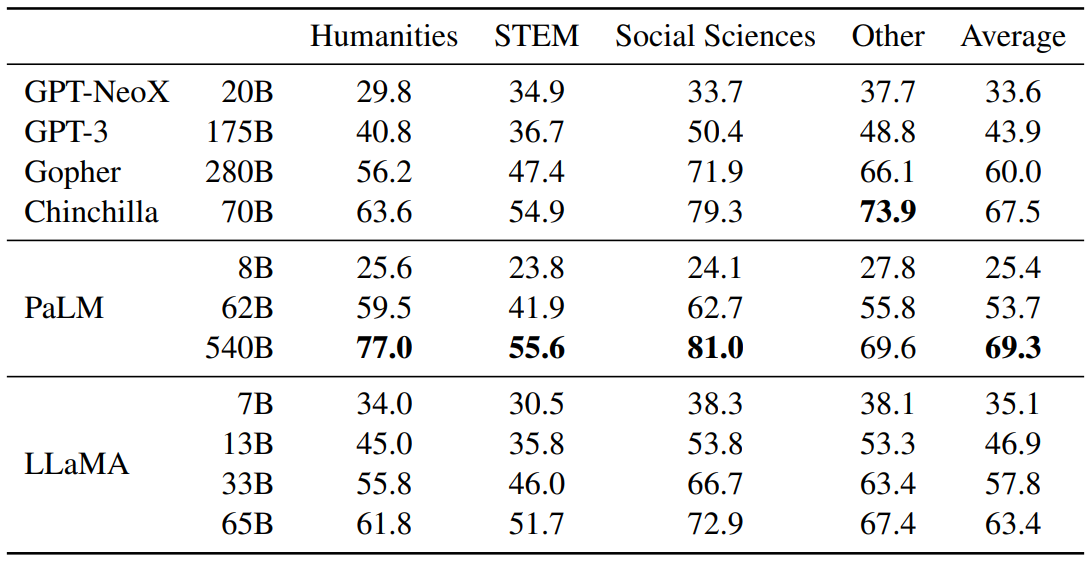
- MMLU 벤치마크 데이터셋 사용
- 다양한 도메인의 질문에 해당하는 multiple choice를 선택하는 task
- 도메인 : humanities, STEM (과학, 기술, 공학, 수학), social sciences
- 5 shot setting에서 평가 진행
- LLaMA-65B
- 거의 모든 도메인에서 Chincilla-70B와 PaLM-540B보다 평균적으로 조금 낮음
- 왜 더 낮은가?
- LLaMA는 총 177GB의 제한된 양의 책과 학술적인 논문들을 사전학습 데이터에 사용하였음
- 다른 모델들은 책 데이터만 거의 2TB로 학습이 진행됨
- 이는 어떻게 Gopher가 GPT-3를 특히 이 벤치마크에서 outperform할 수 있었는지에 대한 설명이 될 수 있다
3.7 Evolution of performance during training


- 몇몇 question answering과 common sense benchmark들에서 학습하는 동안의 성능을 추적했다 (Figure 2)
- 대부분의 벤치마크들에서 성능은 꾸준히 향상했고, 모델의 perplexity와 상관관계가 있었다 (Figure 1)
- 다만, SIQA와 WinoGrande는 예외였다
- SIQA : 학습 도중 성능의 변화가 너무 커서 신뢰할 수 있는 벤치마크가 아니라는 사실을 확인
- WinoGrande : 33B와 65B의 training Loss 차이가 있었음에도 불구하고, 성능이 학습 내내 유사하게 나와서 상관관계가 없는 것을 확인